SEANetMap: Architecture
Table of Contents
1 Document status
This is Draft 2015-05-07-01 of John Tigue's architectural overview of the SEANetMap project.
The other documents in this set can be found in the index.
On Thursday, 2015-05-07 this document was migrated into the project's wiki.
https://github.com/codeforseattle/seanetmap/wiki/Architectural-overview
Feedback can be given (and is most welcome, email such to john@tigue.com).
1.1 Version history
The version are named with the pattern DATE-SERIAL, where DATE is of the from YYYY-MM-DD and SERIAL is a two digit code, reset to 0l each day. For example, 2015-05-04-01 is the first release of May 4th, 2015.
- 2015-05-05-01
- First public release
- A very rough draft, published simply to announce that work was proceeding on it.
- 2015-05-04-01
- Linked via email
- First version worth even reading. Represents a brain-dump by John Tigue after wrapping his head around the complete project scope, and not scope.
- 2015-05-05-01
- cleaned up text
- added more broadband provider names
- fixed links
- 2015-05-07-01
- First diagrams
- A very rough draft, published simply to announce that work was proceeding on it.
2 Introduction
SEANetMap is a join project between M-Lab and Code for Seattle with the goal of developing a liberally licensed, open source codebase for citizens to run broadband network performance tests and compare their results with what other people are experiencing across the area and network providers. The aggregate results dataset is to be publicly available as a social good for further analysis, yet provided in a fashion that respects concerns regarding personally identifiable information.
Initially, the project will be specific to Seattle, yet it is a goal to make the codebase reusable for deployment in other localities.
This document is an architectural overview of the project.
3 Caution regarding development risks
Even though SEANetMap is a not-for-profit open source project rather than a commercial product, it is intended to be quickly consumed by non-technical end users at a decent volume of traffic. As such it may well be wise to not go further out on any more technology limbs than is required.
Consider a 2015-03-30 article, entitled Choose Boring Technology, which councils caution regarding the explore-versus-exploit trade-offs implicit in architectural choices. Basically, the article provides a list of self-check questions for any architect.
"Let's say every company gets about three innovation tokens. You can spend these however you want, but the supply is fixed for a long while."
This mindset has guided the choices as described in this document, at least for the first major release which is all this document is concerned with.
3.1 JavaScript justification
This section can be skipped by any reader already on-board with using NodeJS as the base for the server. JavaScript in the client browsers is not a controversial choice for this project, as without such the maps (Leaflet base) would not work and the network tests could not be performed.
In a certain easiest-way-forward sense, the decision to use JavaScript as the primary coding language was made before Code for Seattle got involved with this project at the meeting of 2015-04-19. The initial code as given to Code for Seattle is written in JavaScript, where "initial code" means the code for the prototype site put together by M-Lab (client-side JavaScript leveraging Leaflet maps, and NodeJS based JavaScript extracting data from M-Lab's data repository and generating GeoJSON maps) as well as the Network Diagnostic Tool (NDT) JavaScript cllent code which works in browsers and NodeJS.
Once JavaScript is a given (as is the case with this project), then NodeJS for the server is a natural choice. NodeJS is simply a JavaScript engine running as net server and has arguable "crossed the chasm" and been adopted by the mainstream web developer community.
Further, the market is rapidly responding to the need for a full ecosystem around NodeJS. In terms of business "social proof" evidence of NodeJS being full-scale ready for prime time web infrastructure consider recent developments out of two of the biggest cloud providers.
- Amazon
- With Lambda, Amazon has essentially recently made NodeJS the event-based scripting engine for all AWS services. AWS will quickly spin up a NodeJS environment and on initialization pass it the AWS service event that just occurred, say, new file uploaded to S3. Then custom bits of JavaScript perform appropriate event handling business, after which the machine is torn down. These microservices have to be short lived (they must end within 60 seconds) yet they are cheap because no continually rented instance.
- AWS Lambda – Run Code in the Cloud | AWS Official Blog
- Why AWS Lambda is a Masterstroke from Amazon | Gigaom Research
- Microsoft
- Microsoft's NTVS (Node.js Tools 1.0 for Visual Studio) brings NodeJS front-and-center into the MS shops. For them Microsoft's Visual Studio can now be used for dev, debug, and deploy-to-Azure of NodeJS. (NodeJS: the Google JavaScript engine! It would seem that post-Balmer MSFT has come to terms with its current reality.)
A single language for both the client and server web-apps makes deeper sense than simply as a specious argument of one language to rule them all. For example, Google DevTools in Chrome is arguably the most impressive debug and performance dev tool to have come out of the last ten years of Open Source Software. NodeJS is based on Google's V8 JavaScript engine so for NodeJS, DevTools is the debugger and perf-tuner for the front-tier of the web-site (which in this case is the site Code for Seattle is working on. M-Lab servers can be seen as deeper in the service and are a complete separate issue).
Point is, there is a lot of not-immediately-obvious evidence which surprisingly adds up to "OK, sure NodeJS" (or, more generally, the all-in-with-JavaScript architectural choice). Of course, there is still tons of non-JavaScript technology needed deeper in the system, but that is not the core issue of this project as M-Lab already has that part going, and further as demonstrated by Amazon's Lambda NodeJS will be penetrating deeper into such system as a solid choice for implementing microservices.
4 Project by component
M-Lab has certainly provided all the basis code needed for a modern looking web site to act as a client of M-Lab's NDT test service and aggregated test results data. In M-Lab's terminology, the codebase that Code for Seattle is working on is called a "portal."
The main goal at this time is to build out a Seattle specific portal. Yet it is very clearly a longer term goal to have a codebase which can easily be deployed by other localities. The Seattle specific site will be useful for Seattle, but might best be viewed as the "pilot system" version 1.0 as we warm up and learn what reusable code will look like and what feature it will have. For example, how will it be white labeled, re-skinned, localized, etc.
Currently, the two codebases provided by M-Lab are still being integrating into the SEANetMap codebase. Those two codebases being:
- a Leaflet map with hexbinned plot of aggregated test speed, where hex color = speed
- a NDT JavaScript test runner with a D3 circle as clock-faced progress bar
The only other concretely define novel feature at this time is:
- a Leaflet map report with test speeds aggregated by Seattle City Council districts
Simply the above two goals with a fully fleshed out dev and deploy process is the current milestone being aimed for. Achieving that would be significant: a new project off the ground, on its own terms, with deployed client and server code. Yet from a longer term perspective that really is only Step One. Although clearly we know where we want to go roughly, many details need to be fleshed out.
For simple organization, the following sub-sections are ordered from the front end (HTML and JavaScript running in a users web browser) to the back end, which for this project ends where the SEANetMap server acts as a client to M-Lab's servers.
4.1 Front end
"Front end" encompasses any HTML, CSS, and JavaScript sent over HTTP to a users browser.
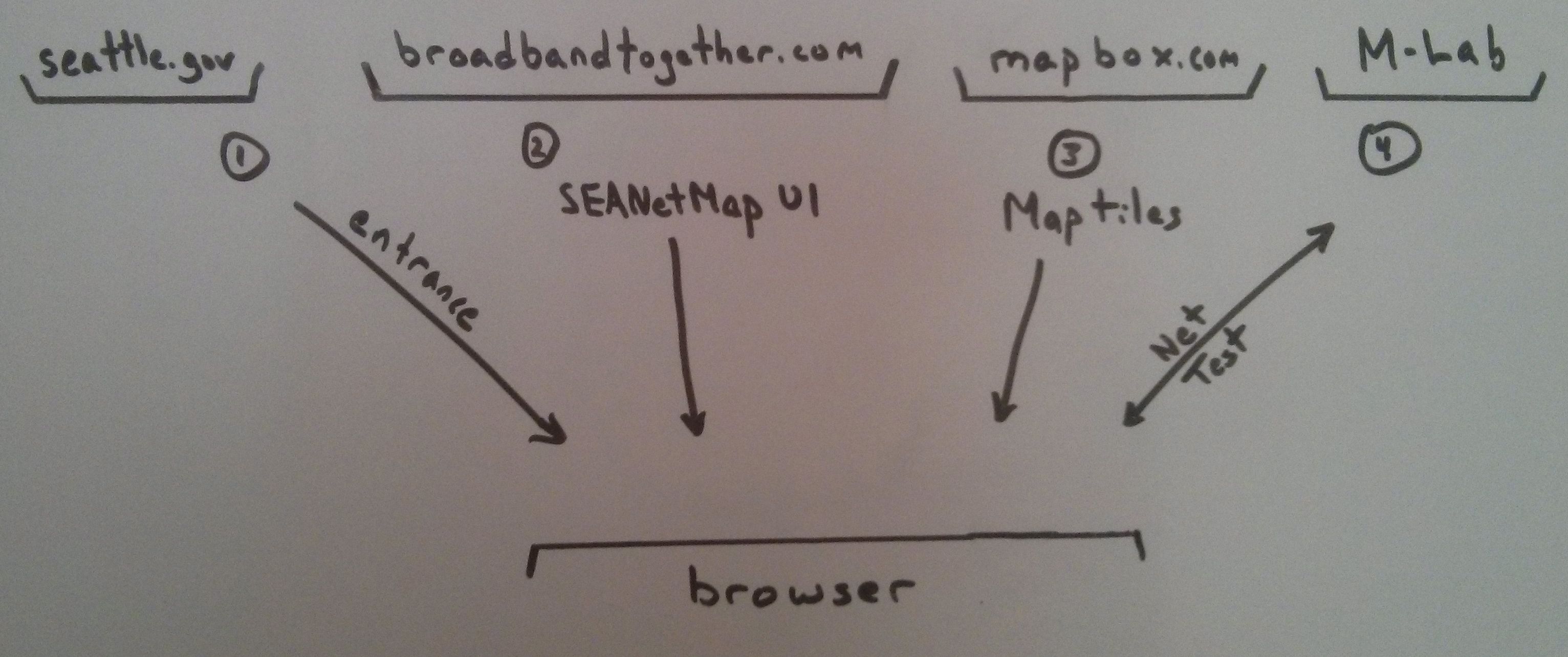
The basic sequence overview from a network traffic view point is:
- The site is somehow arrived at, which will at least be a link from http://seattle.gov.
- The main UI (HTML, JavaScript, images, CSS, etc) is loaded into the browser
- During initialization, map tiles are loaded from MapBox
- Optionally, during the session the user may preform a network performance test against M-Lab servers.
4.1.1 User registration
Registration should be possible with various levels of anonymity, and users should be able to identify themselves more AND less later if they wish.
Registration enables a user to run multiple tests over time across multiple session and the site will be able to show the user a time series plot of their test results.
Various features include:
- Allow completely anonymous use of the site
- Anonymous must be a clear option
- Opt-in for any PII must be very explicit
- Enable users to register via an email address
- Allow users to login using existing external OAuth credentials, such as
- github: http://wplift.com/login-wordpress-using-github
- Reddit: http://www.sanwebe.com/2014/11/creating-reddit-login-button-in-php
- of course other, more mainstream social networks
- Have a "Remember me on this computer" toggle
- Have text making it clearn what "anonymous but remembered" means
4.1.2 Provider identification
There needs to be a dialog wherein users can identify their broadband provider.
For Seattle the listed options should include (amongst others?):
- CenturyLink
- Clear
- Comcast
- CondoInternet
- Dish
- Frontier
- Verizon
- Wave
- and Resellers?
Automatic provider detection is technically possible but is out of scope for now. Manual is sufficient, and even if automatic were built out, there are still cases where the user would want to override that.
Clearly this should not be hardwired into HTML. Whether it comes out of a config file or a database it yet to be determined.
4.1.3 Run and store network tests
M-Lab servers are running the tests in terms of performing as NDTP servers, and they store the results of the test. SEANetMap triggers the test and its web pages host the UI for the test. This provides SEANetMap a hook into the workflow so that it can persist its own information about test run. For example, if a user is logged in and wants to see their previous test from other sessions, then SEANetMap needs to maintain that list of tests. Therefore, it needs to persist to storage the identities of tests run so that the specific past test results can be queried of M-Labs.
The initial 1.0.x UI for the test will be based heavily on the example provided by M-Labs.
- Currently only collecting testers IP
- issue #5, could be gathering geo-location using HTML5 APIs
- The CSS is funky said willscott
4.1.4 Various data visualizations
The test report visualizations will be the main value of this project. There are many possibilities, some are listed here. For 1.0.x only the basics are being aimed for. In particular any reports which require charts may be punted on. This may seem harsh but simple map reports are happening first as M-Lab provided code for such. Charts will happen second. They will be implemented in D3 and D3-based charting libraries such as C3.js.
- Map centric
- Test results aggregated by Seattle City Council District
- Test results aggregated by regular hex tiling of the city
- Heat maps rather than hexes (definitely not in scope for 1.0.x)
- Provider centric
- Test results aggregated by broadband carrier
- Test results aggregated by price of service
- User centric
- a time series plot (maybe time of day/week as well) of a registered user's history of test results (upload, download, and latency). This seems relatively basic, but not it is not basis so it is not clear if this will make it into version 1.0.x
- a time series plot for some geographical sub region ("What are my neighbor experiencing?") This is not basic an will probably not be part of 1.0.x
Note:
- YonasBerhe started working on a viz implemented via angular-leaflet-directive (AngularJS hosting Leaflet)
- But "This portion of the project has been taken up by brett. (Data Visualization)"
- Not sure where that effort is at
4.1.5 Net mapping tool similar to mtr
As per the home page of mtr
"combines the functionality of the 'traceroute' and 'ping' programs in a single network diagnostic tool."
One look at a screen shot and it is easy to image the same UI implemented (better) in DOM/JavaScript, hopefully even a highly interactive D3-based visualization.
It looks like Brett Miller has put a lot of nice work into just such a net mapping tool. The repo is at https://github.com/brett-miller/seattle-internet-analysis
This will hopefully be part of the site but the code is not in the main codeforseattle/seanetmap repo yet.
This code base is Python but there is really no Web server besides use of the venerable SimpleHTTPServer for dishing up static files. So, any static files needed by his code will be served up by nginx.
Somehow there will need to be scheduled process which kicks off this Python code to generate new route maps, but this will be very similar to how bq2geojson (NodeJS) is scheduled and drops into an external process to actually do the heavy lifting of talking to Google's BigQuery.
- mtr-js
Note that Miller's code is Python code. So this is not a direct re-implementation of mtr functionality in the browsers, rather it maps out the network from a server. There might still be a possibility of a mtr-js but that is out of scope now and we do not even know if the WebSocket API provides control of TTL which would be need to make it happen.
4.1.6 Map layers
There should be multiple layers to the map.
[X]Hex tiling of city.- Political boundaries which for the initial site (Seattle only) is the Seattle City Council District boundaries
[ ]Seattle City Council Districts[ ]Census block[ ]Census tracks
(Note, census tracts are larger than census blocks. Seemingly these boundaries are readily available in GIS software. Aggregating by block is finer info so probably preferable.)
[ ]Provider service areas so that users can see where particular providers are operating. (There may be sub-sets, say, CenturyLink's fiber area, fiber to the home, etc.)
For a user to configure the map view they are interested in (in terms of which layers to have rendered), there will need to be a basic layer switcher control.
4.1.7 Dependencies
Various existing codebases are used in the project. Here is a list of known current dependencies.
- Leaflet: for mapping. There is no competition.
- Mapbox: Also for mapping. It is currently in the code base. Have not figured out what it is being used for. Mapbox is heavily based on Leaflet. The Leaflet lead dev now works at Mapbox.
- Bookstrap: Pretty standard for base UI stuff these days. To keep things feeling fresh, the settings need to be tweaked to be somehow not the defaults.
- jQuery: will it ever go away. Why does it persist? It is in the code base.
- D3: Used in the NDT performance test UI. Later it will be used for various charting (say, C3 or custom).
- NDT (natch): this is the NDTP client which does the WebSocket work horse nitty gritty.
Regarding the NDT code:
- critzo: "Internet 2 will soon be releasing NDT v3.7.0 (ndt-project/ndt#162), adding among other features Websockets support to enable a javascript native NDT client. Once this version is released, M-Lab will deploy it to our platform and update our client code to use our production servers rather than the test server it now points to (https://github.com/m-lab/ndt-javascript-client). After that's all done, the Seattle test code should be updated to include the most current production code."
4.2 Back end
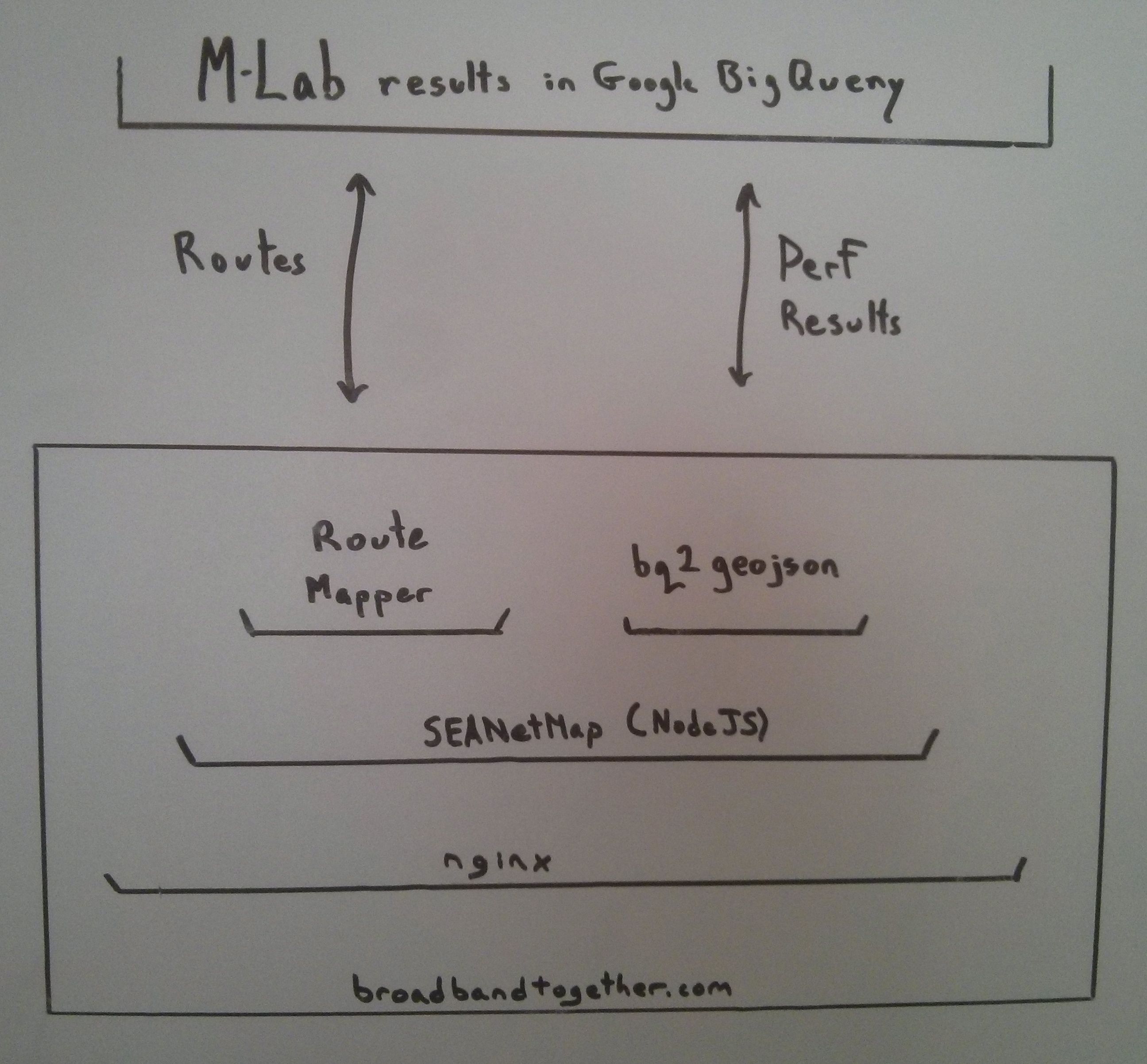
At its core SEANetMap is a NodeJS application. In this diagram broadbandtogether.com is simply a dummy deploy site; SEANetMap will be deployed many places, including firstly by the City of Seattle. In production deploy contexts NodeJS apps live behind reverse proxies, which in this diagram is nginx. SEANetMap serves up the user experience via a web server front end.
Behind the scenes worker task (called services) are scheduled. The two primary ones at this time are:
- bq2geojson:
- regularly builds maps by querying M-Lab for its historical test results stored in Google Big Query.
- Results should be caching of course and only new results queried for.
- at the heart of this process, Node starts a child process which calls Google bq CLI tool, passing it a NOSQL query file
- Results are cached locally as CSV files.
- Turf is used to aggregate the results into various bins to render maps of test results by:
- Seattle City District
- US Census track
- US Census block
- regular hex grid (to be a heat map eventually, hopefull)
- Brett Miller's route mapper
- This is python code
Both of the above hit M-Lab for data, one for routes and one for network performance results.
4.2.1 Web server
The web app is NodeJS-based. The main framework is Express.
- Static content should be hosted on a CDN.
- Currently any dependency with code in a CDN is to be leveraged. E.g. bootstrap, jQuery
- There should be a front (nginx) and a Node supervisor.
- There should be logging (via Bunyan to DTrace)
4.2.2 Services
4.2.3 SEANetMap data store
- Status
This is rather undefined at this time. A SQLite database is initialized but it is not known at this time what is being done with it, if anything. Main issue currently is codeforseattle/seanetmap#4.
- per-nilsson is on this front: "I'll take this on. Will store JSON in a text column in a sqlite database for now."
- Currently, there is a minimal database: essentially just one table for storing JSON of test
- seanetmap/setup-db.js
dbConnection.run('CREATE TABLE test_results (json_data TEXT, ip_address TEXT, created_at TEXT)');- As of , DB set up is documented in the README.
- Possible directions
- Might be PostgreSQL eventually but sqlite at this time
- Mongo is used for this as well, although recent releases of PostgreSQL make it less important.
- We really don't know what data will be stored beyond what M-Lab keeps. They intentionally do not store PII, while that may not be a concern in this project, especially if we very clearly ask the citizens for permission to store PII.
4.2.4 M-Lab interfacing
There are two pieces of technology from M-Lab that are interesting for the purposes of SEANetMap acting as a client to M-Lab: bq2geojson and Telescope. The former is Node code so it would seem to be a natural fit for SEANetMap, while the latter is Python code but is more mature code, lower level, and broader in scope. It would seem that both will be used.
- bq2geojson
- code: https://github.com/m-lab/bq2geojson
- demo: http://files.opentechinstitute.org/~kinkade/bq2geojson/html/
The demo is an animatable map of network performance test results. Each "frame of the movie" is a GeoJSON file generated by bq2geojson
- This is pretty much a solo work by Nathan Kinkade
- A Node command line tool for extracting data from M-Labs and plotting it in GeoJSON, one GeoJSON map per month.
"A tool to (relatively) easily convert M-Lab BigQuery data into hexbinned GeoJSON files and files necessary to make functional maps.
"This is small Node.js application which aims to make it relatively easy for just about anyone to fetch M-Lab data from Google BigQuery and convert it into a format (GeoJSON) that is easily usable by mapping software, Leaflet in this particular case."
So, good that it is Node based, and it is very specific about what it does: make GeoJSON from M-Lab queries. And it is already tested with Leaflet, which the project uses.
- From the README.md:
- "You will also need to have the Google Cloud SDK installed"
- Because for actual data fetching it:
- https://github.com/m-lab/bq2geojson/blob/master/index.js#L274
- var exec = require('childprocess').execSync;
- var result = exec('bq query ' + bqopts + ' "' + query + '"', {'encoding' : 'utf8'});
- Then it uses Turf (server side, before run time i.e making static files for later servering via http server)
- There are 2 files (one for upload info and one for download info) which contain queries that will be made of BQ
- https://github.com/m-lab/bq2geojson/tree/master/bigquery
- these queries both have a single placeholder `TABLENAME` which the JavaScript will replace with a specific yearmonth value before executing the query
- High level:
- bq2geojson is invoked via the command line with a year and optional months as CLI params
- bq2geojson does some housekeeping (creating dirs, preparing NOSQL queries)
- a childprocess is kicked off use Google's bq CLI util for fetching a month's data as CSV.
- actually 2, one for upload info and one for download info
- Google returns a CSV file
- the file is converted from CSV to GeoJSON.
- Turf is used to hexbin the data.
- The result is a set of static files, GeoJSON, one for each month requestd.
- The files sent from the server to the client, if they are actually GeoJSON then this seems like an excellent place to deploy TopoJSON. Hexes should be "compressable" about 6:1::GeoJSON:TopoJSON As is the files do seem to load rather slowly but that could be a number of issues.
- Telescope
https://github.com/m-lab-tools/telescope Telescope is a Python library by M-Lab for querying their Google BigQuery datastore.
- This could be a way SEANetMap gets data out of M-Lab and stored locally.
There are tools for Node to work with Python code, so the bridge could be made:
4.2.5 M-Lab services
The project's wiki already has a page of M-Lab related information, which will not be repeated in this document since this document itself is to eventually be a page in that wiki.
SEANetMap is only a client of M-Lab's data. It does not tightly integrate with M-Lab servers and data store. NDTP tests are run against M-Lab server (for setting up and managing the test and pumping test data through pipes). The bulk of the test result data is stored in M-Lab.
SEANetMap stores additional information, linked to the tests, in its own datastore. This includes PII which is intentionally not gather by M-Lab for reason relating to privacy concerns in the context of intrusive governments in certain parts of the world.
- Notes on M-Lab DB schema
- https://github.com/m-lab/bq2geojson/blob/master/index.js#L160
- seems NDT results are stored in table by yearmonth.
- https://github.com/m-lab/bq2geojson/blob/master/index.js#L160
5 Out of scope
5.1 Heat maps
A heat map would be nice, once there is sufficient data. Leaflet does have facilities for heat maps:
But again, it might be something for later when there is enough data to have a smooth heat map. Nonetheless, it is not critical or base simplicity so it is off the list for 1.0.x. If things go amazingly well, perhaps this could be a stretch goal.
5.2 Automatic provider identification
M-Lab stores route information (Paris traceroute) gathered during the NDTP tests.
This information includes identifying information of the various routers that the TCP/IP packets pass through between the test client and server.
Although the following is not M-Lab related, consider this output from a mtr:
1. qwestmodem.domain.actdsltmp 0.0% 20 3.4 3.8 1.8 9.5 2.5 2. tukw 0.0% 20 24.4 28.8 22.8 75.4 13.2 3. tukw 0.0% 20 23.7 24.9 22.2 40.2 3.9 4. sea-edge-12.inet.qwest.net 0.0% 19 26.9 25.4 23.1 29.6 1.6 5. 63-158-222-114.dia.static.qwest.net 0.0% 19 23.6 24.4 22.7 28.7 1.4 6. 66.249.94.212 0.0% 19 26.4 28.2 23.1 68.8 10.9 7. 216.239.51.159 0.0% 19 23.3 24.2 22.7 27.7 1.3 8. clients4.google.com 0.0% 19 28.7 24.7 23.2 30.7 2.0
Point being, from the "qwest" info from DNS, this is a CenturyLink customer. It would be very nice to pre-set a users ISP details based on such trivial look-up conclusions. This is out of scope for 1.0.x. The user will have to identify their provider manually, initially.
5.3 Containerization
Post 1.0.x the code will be segregated into containerizable components suitable for deployment via Docker. A Dockerized architecture is a good target for maximizing re-deployability, which also encourages a microservices architecture, which is a natural fit for this project wherein a SEANetMap server has to work with M-Lab's separate servers over HTTP.
It would be nice to do this for 1.0.x but time is very tight so there will have to be a refactorization later. This actually is not such a bad thing because the project is so nascent that the structure is still being explored. Long term though this is a goal.